FAQ¶
We try to answer here some commonly asked questions about Fortran. If the answers are subjective or incorrect, please let us know (preferably by sending a pull request fixing it, see the main page).
What is the advantage of using Fortran (as opposed to for example C/C++)?¶
Fortran is built from the ground up to translate mathematics into simple, readable, and fast code – straightforwardly maintainable by the gamut of mathematicians, scientists, and engineers who actually produce/apply that mathematics. If that is the task at hand, it is the right tool for the job and, as right tools tend to do, can save enormous time and pain, with most excellent results. If, however, mathematics is not the main task, then almost certainly C/C++, or a host of other more general-purpose languages, will be much better.
The design goals of the C++ language are (citing Bjarne Stroustrup talking about the aims of the C++0x standard): Make C++ a better language for systems programming and library building – that is, to build directly on C++’s contributions to programming, rather than providing specialized facilities for a particular sub-community (e.g. numeric computation or Windows-style application development). (See also the specific aims.)
On the other hand, the Fortran language has been designed with the following goals (see for example the review article The Seven Ages of Fortran by Michael Metcalf):
- Contain basic mathematics in the core language (rich array operations, complex numbers, exponentiation, special functions)
- Be more restricting (and higher level) than languages like C/C++, so that the resulting code is easier to maintain and write and easier for the compilers to optimize (e.g. pointers are purposely restricted so that they can be more highly optimized than C pointers, Fortran arrays are designed in such a way that compilers can check for size and shape mismatches at compile time and index errors at run time, etc...). There is one canonical way to do things and you don’t have to worry about memory allocation (most of the times).
- Speed
An important point is that having all the basic elements in the language itself greatly simplifies both writing and reading fast, robust code. Writing and reading is simplified because there is a single standard set of functions/constructs. No need to wonder what class the array operations are coming from, what the member functions are, how well it will be maintained in 5 years, how well optimized it is/will be, etc. All the basics are in the language itself: fast, robust, and standard for all to read and write – and for the compiler writers to optimize at the machine level.
What are good books to learn Fortran from?¶
We have found, Metcalf, Reid, & Cohen: Modern Fortran Explained, to be quite helpful in providing both the larger context of the language as a whole and a clear, well-connected presentation, organized by standard: f95, f2003, and f2008.
Another good book with a lot of examples is Stephen Chapman: Fortran 95/2003 for Scientists & Engineers. And a reference book Adams, Brainerd, Hendrickson, Maine, Martin & Smith: The Fortran 2003 Handbook.
Other books can be found for example at fortran.com/metcalf.htm
However, Fortran is relatively quick to learn because it is so much simpler and smaller than C/C++ (in practice, that is, with all needed libraries included).
What are other good online Fortran resources?¶
We have found the following links to be quite helpful:
And the Fortran standards:
- WG5 Fortran Standards Home: https://wg5-fortran.org/
- FORTRAN 66 standard: https://wg5-fortran.org/ARCHIVE/Fortran66.pdf
- FORTRAN 77 standard: https://wg5-fortran.org/ARCHIVE/Fortran77.html
- Fortran 90 standard: https://wg5-fortran.org/N001-N1100/N692.pdf
- Fortran 95 standard: https://wg5-fortran.org/N1151-N1200/N1191.pdf
- Fortran 2003 standard: https://wg5-fortran.org/N1601-N1650/N1601.pdf
- Fortran 2008 standard: https://j3-fortran.org/doc/year/10/10-007r1.pdf
- Fortran 2018 standard: https://j3-fortran.org/doc/year/18/18-007r1.pdf
Compiler table for support for the 2003 and 2008 standards appears regularly in Fortran Forum. The 9th revision: fortran_2003_2008_compiler_support.pdf.
How to do dynamic dispatch in Fortran (like ‘void *’ in C)?¶
The equivalent of void * in Fortran is type(c_ptr), see Type Casting in Callbacks for examples of usage.
How to interface Fortran with C and Python?¶
Just use the iso_c_binding module to interface with C, see Interfacing with C for more information and examples.
Once you can call Fortran from C, just write a simple Cython wrapper by hand to call Fortran from Python, see Interfacing with Python for more info. You can also use f2py or fwrap.
What is the most natural way to handle initial and final points of intervals?¶
Dijkstra considers 4 possible ways to handle intervals:
- 2 ≤ i < 13
- 1 < i ≤ 12
- 2 ≤ i ≤ 12
- 1 < i < 13
What is the natural way to handle the initial and final point of an interval of numbers/objects? Of course, there is no one most natural way for all cases. However, for the vast majority of cases, be they mathematical, scientific, or natural language, inclusion of endpoints appears most natural – and so least mistake prone. To get a sense, consider, for example, the following:
- You say that John Doe lived from 1914 to 1955. It means he was born in 1914 and died 1955, it does not mean he was born in 1915 or died in 1954.
- In your CV, you say you studied at MIT from 1979 to 1984. It means you started in 1979 and ended in 1984, it does not mean you started in 1980 or ended in 1983.
- Consider, there is a line up of 10 people, and you want to divide them into three groups. You do not say I want group one to start with Peter and end with Jane, and group two to start with Jane, and end with Tom, and group three to start with Tom and end with Frank.
- In math, you say “count the numbers 1-100”, it means from 1 to 100, not from 1 to 99, or from 2 to 100.
- The mathematical symbol
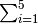 means adding terms with
means adding terms with 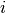 from 1 to
5 (inclusive), it does not mean from 1 to 4
from 1 to
5 (inclusive), it does not mean from 1 to 4 - When you write 1..10 in an email, it means 1 to 10, including both ends
Conclusion: these real life examples show that the case c) is the most natural.
What is the most natural starting index for numbering?¶
Let’s look at a few examples:
- Test questions always start with 1.
- Literature in articles always starts with 1.
- When you divide people into groups (e.g. at a gym), you let them count numbers (e.g. 1 to 5) periodically to divide them into 5 groups. You do not start with 0 and you don’t have a group 0.
- Babies count their fingers as 1-5, not 0-4.
- House numbers (in an address) start with 1
- You say “I finished first”, not “I finished zeroth”
- In atomic physics, the n quantum number is from 1 to n_max and the angular momentum quantum number l is from 0 to n-1
- For quantum harmonic oscillator, the n quantum number is from 0 to n_max and the angular momentum quantum number l is from 0 to n
- The z-component of angular momentum is from -l to l.
- Dirac kappa is from -kappa_max..kappa_max, without 0.
- FFT frequencies (for 2*n sequence) are from -n+1, ..., n (the standard ordering actually is 0, 1, ..., n, -n+1, ..., -1)
Conclusion: As shown by the many examples, numbering does not always start most naturally at one or zero. And so to force any one choice for all cases — one size fits all! – be it 0-based or 1-based, is inevitably unnatural – and with that, more likely error prone and hard to debug/maintain. However, the most common starting index is 1.
Why does Fortran default array indexing start at 1?¶
Because that is the most commong starting index (see previous question).
What is the motivation behind Fortran numbering convention?¶
The whole point of Fortran arrays is to allow the user to index them as most natural, and thus least error prone, for the mathematics being rendered. Hence, one can declare a(1:3), a(-1:1), etc. And since the vast majority of enumerations in everyday life, mathematics, and science start at 1 (see What is the most natural starting index for numbering?), Fortran makes that the default unless the user explicitly wants otherwise. It’s just a nice convenience, in a world of hundreds or thousands of array declarations in a typical code, to be able to declare as a(3) rather than always having to specify beginning and ending indices for every declaration when, almost always, these would just start at 1. This becomes all the more convenient and character-saving in the context of multi-dimensional arrays. E.g. to be able to declare simply a(m,n,p) rather than a(1:m,1:n,1:p) all over the place is rather nice, and quick and clear to type/read (and not mistype/misread).
As to slicing (or “sections” as it is called in Fortran), the most natural is to include both endpoints (see What is the most natural way to handle initial and final points of intervals?). So if it’s test scores, a(1:n) gets the “first through nth” scores. If its angular momenta, a(-2:2) gets the “-2 through +2” values. a(:) means, simply, “first through last” elements of array a regardless of indexing. Omitting the first index means “first element of a, regardless of chosen indexing”; omitting the last index means “last element of a, regardless of chosen indexing”.
For some examples of a side-by-side comparison of Python vs Fortran array indexing, see the Python Fortran Rosetta Stone, specifically the section about Some indexing examples.
What is the motivation behind the C/Python numbering convention?¶
For C, a good motivation is given by Edsger Dijkstra (1982): http://www.cs.utexas.edu/users/EWD/ewd08xx/EWD831.PDF
The author of Python, Guido van Rossum, has provided motivation behind the Python convention here (2013): https://plus.google.com/u/0/115212051037621986145/posts/YTUxbXYZyfi
Does Fortran support nested functions?¶
Yes, see Nested Functions for examples of usage.
How to implement functions that operate on arbitrary shape arrays?¶
You can use the elemental keyword to implement subroutines/functions that can operate on arrays of any shape. Other approaches are to use reshape or explicit-shape arrays. See Element-wise Operations on Arrays Using Subroutines/Functions for examples of usage of both approaches.
Are Fortran compilers ABI compatible?¶
No, in general Fortran compilers are not ABI compatible. Things that are different:
- Run-time library: different for each compiler. For the given compiler, most of the time the library is backward compatible (for example libgfortran of GCC 4.7 is compatible with 4.6, 4.5, 4.4 and 4.3; 4.5 is compatible with 4.4 and 4.3. But 4.2 has a different .so version and is incompatible with either 4.1 and 4.3.)
- Modules: convention for naming and symbol mangling
- Trailing underscores (zero, one (most common), two)
- Calling convention: Whether real is passed as double, whether a function returns the value as first argument, etc. (see for example the -ff2c option in gfortran)
- Logical: Special Intel vs. gfortran problem: Intel has -1 as .true. and gfortran 1. With higher optimization levels, gfortran only looks at one bit, hence -1 is .false..
- ...
On the other hand, Intel C and C++ compilers are ABI-compatible with GCC and Clang.
What is the best way to distribute and install Fortran libraries?¶
The best way is to simply provide the library as modules with source. That way, compilers can optimize to the particular hardware and there are no object-file incompatibility issues – and the user can extend/modify the module for his own purposes.
Due to ABI incompatibility, in general the .so/.a libraries compiled with one compiler version cannot be used with any other compiler or version.
As such, the only two options are:
Distribute different .so/.a for each compiler (to some extent, they can be used with different versions of the same compiler, see Are Fortran compilers ABI compatible?).
This means to either provide source code and the user compiles it using his compiler, or precompile it with each compiler version (for commercial libraries). Either way, once we have .so/.a compatible with our compiler, there are generally two ways to call it from a program:
1.1. Distribute .mod files, that are compiler version dependent (In case of gfortran, they are only compatible between releases (4.5.0 and 4.5.2) but not between minor versions (4.5 vs 4.6))
1.2. Distribute interface .f90 files, that contain the “abstract interface” for each subroutine/function, those are compiler independent, but they don’t work for modules. The upcoming Fortran standard for “submodules” will make this work for modules as well.
Provide C interface (see Interfacing with C) and distribute just one .so/.a.
The library would be indistinguishable from any other C library, and it would be used from Fortran like any other C library. This of course means that one cannot use Fortran features not available through the C interface (currently: assume shape arrays, allocatable arrays, pointer arrays, but those will all be eventually available in future Fortran standards).
Unless the ABI becomes compatible across compilers, the easiest is to use 1.1. for Fortran usage, and 2. for C/Python usage. (If the ABI became compatible let’s say at least between ifort and gfortran, it might make sense to use 1.2. and distribute only one .so/.a).
Note I: Distributing the .a file only (as opposed to both .so and .a files) for the given platform/compiler should be enough in many cases as it is faster and the number of programs sharing the library on any given system is typically fairly low.
Note II: The advantage of distributing the sources is that it allows to optimize for the system at hand (e.g. GCC’s -march=native option), as well as for more specialized machines like BlueGene.
See this thread for more information.
Does Fortran warn you about undefined symbols?¶
Yes, it does. For gfortran, you need to use the -Wimplicit-interface option.
What is the equivalent of the C header files in Fortran?¶
Create a module and use it from other places (see Modules and Programs for more information). The compiler will check all the types. However, there is a difference from C in how to distribute Fortran libraries, see What is the best way to distribute and install Fortran libraries? for more information.
What compiler options should I use for development?¶
One possibility for gfortran is:
-Wall -Wextra -Wimplicit-interface -fPIC -fmax-errors=1 -g -fcheck=all -fbacktrace
This warns about undefined symbols, stops at the first error, turns on all debugging checks (bounds checks, array temporaries, ...) and turns on backtrace printing when something fails at runtime (typically accessing an array out of bounds). You can use -Werror to turn warnings into errors (so that the compilation stops when undefined symbol is used). With gfortran 4.4 and older, replace fcheck=all with -fbounds-check -fcheck-array-temporaries.
For Intel ifort:
-warn all -check all
What compiler options should I use for production run?¶
One possibility for gfortran is:
-Wall -Wextra -Wimplicit-interface -fPIC -Werror -fmax-errors=1 -O3 -march=native -ffast-math -funroll-loops
This turns off all debugging options (like bounds checks) and turns on optimizing options (fast math and platform dependent code generation). One can also use -Ofast instead of -O3 -ffast-math.
It still warns about undefined symbols, turns warnings into errors (so that the compilation stops when undefined symbol is used) and stops at the first error.
For Intel ifort:
-warn all -fast
How do I indent free-form Fortran source code in a consistent manner automatically?¶
If your editor or IDE does not support automatic indentation, you may want to use Emacs’ batch mode instead:
emacs --batch filename.f90 -f mark-whole-buffer -f f90-indent-subprogram -f save-buffer